表計算ソフトやワープロソフトなどのファイルは、テキストファイルではあり ません。表計算ソフトやワープロソフト (Excel, Word など)が作るファイル は、 表示する文字のデータだけでなく、それをどのように表示するかという フォントやレイアウトの情報、貼り込まれた画像の情報なども含みますし、文 字自体もそのソフト特有の形式で記録されていたりします。テキストファイル は、そうした情報をいっさい含まないファイルです。
各列がそれぞれひとつのデータ項目に対応し、各行はひとつのサンプルのデー タという形式のテキストファイルだと、 read.table 関数を呼び出 すことで読み込めます。データの区切りは 空白かタブ なら特別な 指定は不要です。またカンマが区切りのファイル (CSV, comma separated values) ならread.tableではなく read.csv とい う関数を使えば同じことができます。以下で述べるように Excel での前処理を 考えると read.csv のほうが利用機会は多いかもしれません。
ここで、CSV も(カンマで項目を区切っている)単なるテキストファイルであ ることを再確認しておいてください。以下は、read.table 関数で読めるデータの例です。ファイルの一行めには各列の内容を表すラベルを書いておくと分かりやすいで しょう。項目名にはアルファベット、数字、ピリオド '.'、下線 '_' が使えま す。最初の文字に数字は使えません。これは、変数名や関数名のルールと同じ です。また、同じ名前が重複してもいけません。こうしたルールに従わない名 前を与えた場合、読み込み時に適当に名前を変形して ルールに従うものにして くれますが、この機能に頼ってしまうと自分が与えたつもりの項目名とR のな かでの項目名とが一致せず、混乱のもとです。できるだけルールにしたがった 名前をつけるようにしましょう。
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 5.1 3.5 1.4 0.2 setosa 4.9 3.0 1.4 0.2 setosa 4.7 3.2 1.3 0.2 setosa 4.6 3.1 1.5 0.2 setosa 5.0 3.6 1.4 0.2 setosa 5.4 3.9 1.7 0.4 setosa ....R では、練習用にいくつかデータが用意されています。上の例は、そのなかの アヤメの仲間の花の形態のデータ (iris) の一部です。このような 表形式のデータを、データフレームに読み込んで処理することがよくあります。 実際のデータマイニング作業では必須の処理ですので、よく理解しておいてく ださい。
なお、read.table,read.csv 関数で読み込むには、各列のデータ数は同じでな いといけません。このデータ構造は、列が測定項目、行がひとつのサンプルに 相当するというような構造を想定しています。
1000サンプルについて、毎年1回、10年にわたって何かを測定した場合は、 行が個体、列は測定月に対応し、当然、すべての列は同じ数のデータを含みま す。しかし、各列が測定年月で、一列には、毎回野外でとってきた不特定数 (200だったり 500だったり)のサンプルの測定データが並んでいるような場合 には、データ数は不揃いになります。この場合、そもそも一行に並んだいくつ かのデータが特別の結びつきを持つわけではありませんし、むりにひとつの表 形式に並べないで、月ごとに別ファイルにしたほうが扱いやすいかもしれませ ん。データの管理にExcel などの表計算ソフトを使っている場合は、それらのデー タを一度テキストファイルにしてから R に読み込んで使います。 表計算のシー ト上で、R で読み込みやすい上の例のようなかたちにデータを並べ、 テキスト ファイルとして保存します。多くの場合は CSV として保存すればよいでしょう。
また、Excel で作成したシートの必要な部分だけを選択・コピーし、あらかじ め開いておいた空のテキストファイルに貼り付けると、列間がタブで区切られ たテキストファイルを作ることができます。ただし、Excel でひとつのファイ ル中にたくさんのシートをまとめて管理している場合、これらをテキストファ イルに保存するには、シート毎に手作業するか、VBA で工夫するかしないといけ ません。
場合によっては、不揃いなデータがあった場合や、2次元の表になっていない など、そのままの形では解析に適さないような場合もあります。 R のなかに 一行ずつ読み込んでから整えるという手もありますが、 テキスト処理が得意な Excel VBA, perl 等のプログラミング言語を使えるならば、それで前処理して しまったほうが簡単かもしれません。
Seiseki <- read.csv("seiseki.csv")
Seiseki
とすれば良いです。ディレクトリの変更を忘れずに先にしておいてください。
あるいは前述の通りSeiseki <- read.csv("I:/rdata/seiseki.csv")と フルパス (full-path, ドライブ名、フォルダ名を全部順番に書いてファ イルを指定するやり方。絶対パスとも言う) で読ませると、ディレクト リの変更をさぼれます。これまた前述のとおり Windows ではフォルダの階層 は \ (Yen, backslash) なのですが、 Rの中では / (slash) で表 現できます。ちなみにこのデータファイルは文字コードを Shift-JIS にしていますので、 Linux, Mac 等で開くと化けるかもしれません。前の "\" の混乱同様、文字コー ドの詳細は略します。
実はR言語では行・列に関する演算 は apply や by のような関数を用いて行うのが普通(?良いとされる)です が、ここでは詳細は略します。Rのfor文は次のような書式です。
for(i in 1:10) {
print(i)
}
ここでは変数iの初期値を1にし、iが10になるまで繰り返し処理を行っています。
【具体例】
サンプルのデータフレームを使って、例を見てみましょう。サンプルは以下の ものとします。
Seiseki <- data.frame( # データフレーム
row.names=c("一郎","和子","花子","二郎","三郎"), # 名前
Sex=factor(c("男","女","女","男","男")), # 性別
Classroom=factor(c(1,1,2,1,2)),# クラス
Japanese=c(45,62,53,32,93), # 国語
English=c(23,82,43,5,73), # 英語
Math=c(67,51,82,21,89), # 数学
Height=c(173,149,122,178,162), # 身長
Weight=c(63,38,39,59,48) # 体重
)
ちなみにこれは、上で読み込んだ seiseki.csv とほぼ同じ情報を持っています。
seiseki.csv を使うなら、
Seiseki <- read.csv("seiseki.csv",row.names=1)
とすればよいです。read.csv の引数 row.names=1 で、行番号は無視させるよ
うにしています。
ここでは例として、行単位にループ処理して各生徒の得意科目と点数を表
示してみます。
【ソースコード】
for(i in 1:nrow(Seiseki)) {
Namae <- rownames(Seiseki[i,])
Tokui <- names(which.max(Seiseki[i,c('Japanese','English','Math')]))
TokuiPoint <- as.integer(max(Seiseki[i,c('Japanese','English','Math')]))
print( sprintf("%sの得意科目は%sで、点数は%d点です。",
Namae,Tokui, TokuiPoint) )
}
nrow は行数をかえす関数,
rownames はその行の名前(ラベル)をかえす関数,
which.max はどれが最大値かを探してくれる関数,
as.integert は数字を数値に変換する関数です。
【実行結果】
[1] "一郎の得意科目はMathで、点数は67点です。" [1] "和子の得意科目はEnglishで、点数は82点です。" [1] "花子の得意科目はMathで、点数は82点です。" [1] "二郎の得意科目はJapaneseで、点数は32点です。" [1] "三郎の得意科目はJapaneseで、点数は93点です。"
while( 評価式 ) {
# 評価式が正の間、この部分が実行されます。
}
repeat文は以下のようになります。
repeat {
# break が実行されるまで、この部分が実行されます。
}
具体例は以下の通りです。
【ソースコード】(while)
n <- 0
while (3^n<=1000) {
print( sprintf("3の%d乗は%dです", n, 3^n) )
n <- n+1
}
【ソースコード】(repeat)
n <- 0
repeat {
if(3^n>1000) break;
print( sprintf("3の%d乗は%dです", n, 3^n) )
n <- n+1
}
【実行結果】
while, repeat どちらの例も、実行結果は同じです。[1] "3の0乗は1です" [1] "3の1乗は3です" [1] "3の2乗は9です" [1] "3の3乗は27です" [1] "3の4乗は81です" [1] "3の5乗は243です" [1] "3の6乗は729です"while, repeat文の使い方は人それぞれと思います。前述の通りR言語では applyなど様々な条件で一括処理をするための仕組みがありますが、繰り返し 処理も使用できるので状況に応じて利用します。
if( 評価式 ) {
print('この部分が実行されます')
}
if( 評価式 ) {
print('評価式が正しい(TRUE)の場合')
} else {
print('評価式が間違い(FALSE)の場合')
}
ifelse(評価式, TRUEの場合, FALSEの場合)例として、上で説明したfor文と組み合わせて、各生徒の性別を英語にして表示 してみます。データセットは上の例をそのまま使います。
【ソースコード】
for(i in 1:nrow(Seiseki)) {
if(Seiseki[i,'Sex'] == '男') {
gender <- 'man'
} else {
gender <- 'woman'
}
print( sprintf("%sは%sです", rownames(Seiseki[i,]), gender ) )
}
【実行結果】
[1] "一郎はmanです" [1] "和子はwomanです" [1] "花子はwomanです" [1] "二郎はmanです" [1] "三郎はmanです"
【ソースコード】
for(i in 1:nrow(Seiseki)) {
gender <- ifelse(Seiseki[i,"Sex"]=="男", "man", "woman")
print( sprintf("%sは%sです", rownames(Seiseki[i,]), gender) )
}
さらに、ifelse文の性質を利用して、for文を使用せずに記述する事もできます。
ただし、結果がベクトル型ですので、全く同じというわけではありません。
【ソースコード】
print(sprintf("%sは%sです",rownames(Seiseki),
ifelse(Seiseki[,"Sex"]=="男","man","woman"))) # ほんとは一行
【実行結果】
[1] "一郎はmanです" "和子はwomanです" "花子はwomanです" "二郎はmanです" "三郎はmanです"rownames(Seiseki[i,]) だとその行の名前を返すだけですが、 rownames(Seiseki) とすると、行の名前の ベ クトル を返してきて、そのそれぞれの要素に対して print(sprintf(...)) を実行しています。
if文は簡単な処理ですが、ベクトルや行列に対して関数を実行可能なRの 性質を活用すると、CやJavaでは見慣れない効率的なコードを作成できる と思います。
plot(Seiseki)と打ち込みます。するとグラフ(散布図)が表示されるはずです。散布図は2つ の変数の関係を分析する際にとても便利なグラフです。
つぎに、
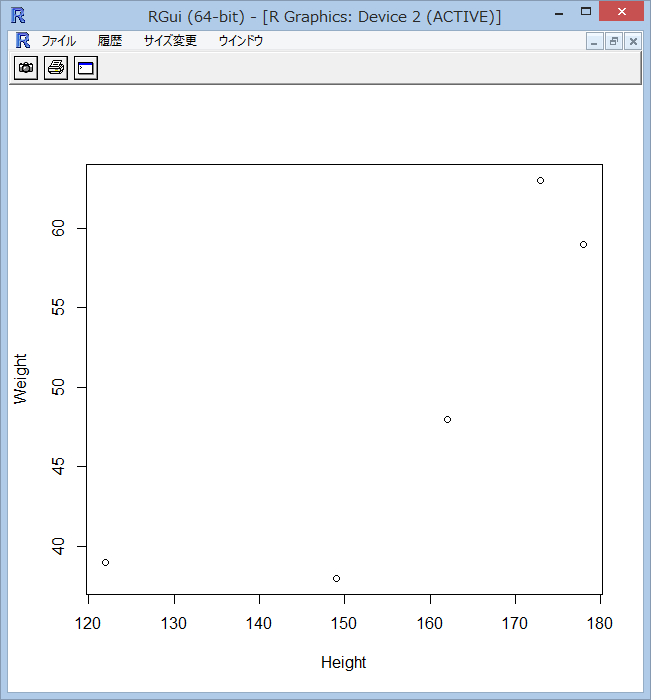
plot(Seiseki[,6:7])と打ち込んでみます。すると、身長と体重を x,y 軸にした図が得られると思い ます。。つまり、Seiseki[,6:7]は、Seiseki の全ての行を選択、6番目の列か ら7番目の列を選択するという意味です。
ts.s<-ts(Seiseki) plot(ts.s[,3:5])と打ち込んでみましょう。すると折れ線グラフが描けます。
ts(Seiseki)は、()内のデータを 時系列 (Time Series) データとして認識させ る関数です。時系列データとは、例えば、日付と一日の平均温度のような、特 定の時間毎に計測されたデータを指します。
このように、R ではデータのグラフ化は非常に簡単です。データの解釈には視 覚化(グラフ化)は非常に大切なプロセスなので、ぜひ覚えておきましょう。